
Industrial Maintenance
4 Reasons Why Predictive Maintenance Does not Work
By Ricky Smith
(Reference: “Rules of Thumb for Maintenance and Reliability Engineers”)
Many companies adopt some form of Predictive Maintenance (PdM) technology as the first step in the path to improved plant reliability. However, the returns from these initial PdM investments often fail to meet the expectations of management. Many of you have seen the ineffective use of predictive maintenance where failures occur even though you are using some type of PdM monitoring. I lived in this world as a maintenance supervisor and it frustrated me that I could not define the use of PdM more effectively. I wrote this article in order to share my experiences with you based on my successes and failures. So let’s look at the top 4 reasons why PdM has failed to meet management’s expectations as I have seen.
In order to define why Predictive Maintenance fails let’s first understand the definitions of “Predictive Maintenance” and “Predictive Maintenance Technologies” or PdM Technologies.
Predictive Maintenance is the monitoring of an asset’s health in order to anticipate the opportunities to proactively perform maintenance to preserve an asset from failure or to protect it in some way. PdM Technologies are the instruments or technologies used to collect asset health data.
The purpose of Predictive Maintenance is to maximize, at optimal cost, the likelihood that a given asset will deliver the performance necessary to support the plant’s business goals. By “optimal cost” we imply that if it is feasible, and economically sensible to perform a task that detects a failure far enough in advance to make intervention practical, then we will have avoided the far greater costs of equipment downtime, secondary damage, as human injury, environmental impact, quality and others.
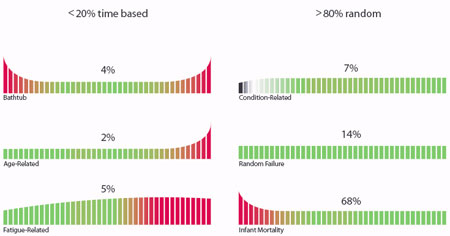
In order to use PdM technology one must under how equipment fails. Through studies we know 20 % of failures are time based and 80% of failures are random in nature and cannot be effectively correlated to time or operating hours. PdM provides one of the major tools to identify the onset of a failure of an asset. PdM use for random failures must focus on the health of the asset (through monitoring indicators such as temperature, ultrasonic sound waves, vibration, etc.) in order to determine where an asset is on the degradation or PF Curve. Point “P” is the first point at which we can detect degradation. Point “F”, the true definition of failure, is the point at which the asset fails to perform at the required functional level. In the past, we defined “Failure” as the point at which the equipment broke down. You can see points P and F and the two different definitions of failure in the graphic below.
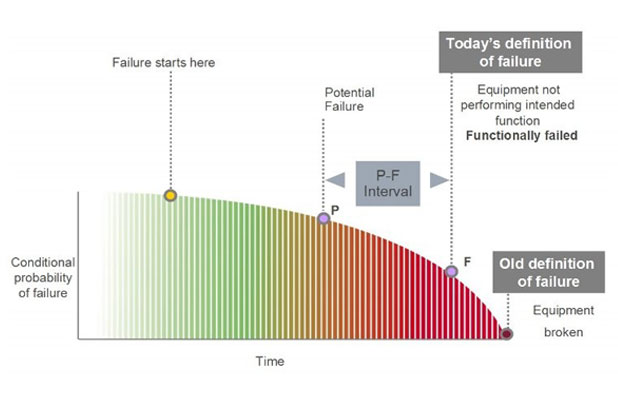
PF CURVE
The amount of time that elapses between the detection of a potential failure (P) and its deterioration to functional failure (F) is known as the P-F interval. A maintenance organization needs to know the PF Curve on critical equipment in order to maintain reliability at the level required to meet the needs of the plant. Without this knowledge how can one truly understand how to manage the reliability of the asset?
PdM should be used to define where on the PF interval is the health of the asset. Defining the point of failure in the PF interval far enough in advance that the asset can have planned and scheduled maintenance performed to restore the asset. As you can now see, understanding failures is very important to understand how to use PdM technologies to its full potential.
Let’s now look at the 4 main reasons that PdM has failed to deliver expected value.
Reason 1: The collection of PdM data is not viewed as part of the total maintenance process.
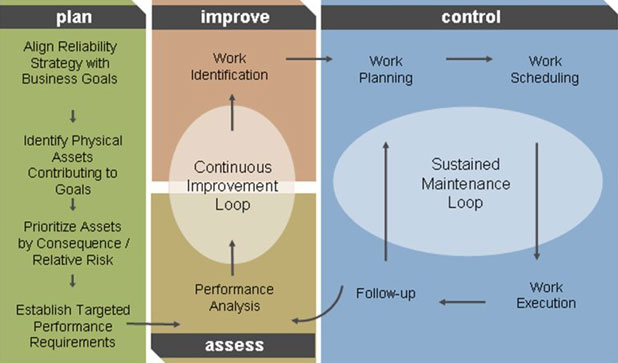
Many organizations, at least initially, view PdM as a separate activity from the core role of the maintenance function, and so it is not covered in the maintenance process. Some organizations start down the PdM path by ”trying it out” on a contract basis. The contractor’s role is to email or snail-mail the resulting predictive data to the plant. In other companies, a PdM resource (often seen as the Reliability Technician) is assigned the predictive role, or a PdM Team is formed. When these individuals or teams are not seen as an integral part of the maintenance department, their value is unlikely to be realized. Also, quite often the predictive data will be supplied to the maintenance organization, but the technician who collected the data is not consulted on the results, so the potential for well-informed data-driven decisions is limited. If PdM is disconnected from the maintenance process, the PdM program will likely fail because the value cannot be identified.
For example, have you ever seen a case where a maintenance employee becomes the new PdM technician? He may be the lucky one picked to operate the brand new $50,000 thermography equipment. In an immature reliability environment, the new role usually comes with a title that includes the word “Reliability”. This new Reliability Technician goes out and starts snapping pictures of assets that show interesting heat profiles (when your only tool is a hammer, everything looks like a nail). But for most of these assets, a reasonably sound failure analysis, if performed, would not identify excessive over heating as the best predictor of failure. Or, potentially even worse, after the failure of a particular asset is determined to be “overheating”, the Reliability Technician is assigned to produce thermographic profiles of every similar asset in the plant -regardless of probability of failure, frequency of failure, failure consequence etc. Is it any wonder that production and maintenance personnel see limited value in the Reliability Technician’s data?
To get the most out of PdM, I recommend that you make it an essential part of the Work Identification and Work Execution elements in your maintenance process. The steps in the Work Identification should clearly identify failure modes, and the best techniques for predicting those failures. PdM tasks are identified as part of a complete asset maintenance program, so we understand why we are doing the work and we are not doing unnecessary work. Work Execution conducts the work specified in the asset maintenance program in the most efficient manner possible. Tasks should be groups in routes and handheld devices used where the PdM technology requires human intervention.
Involve production, maintenance and PdM personnel in failure analyses and the resulting work execution. In this way, we ensure that the prescription for failure management applies our PdM capabilities where they are most valuable. The involvement of these groups also ensures that the predictive data will be welcomed and seen as valuable as it arrives.
Reason 2: The collected PdM data arrives too late to prevent equipment failures.
In this scenario, maintenance and operations management ask “Why did we not see this equipment failure coming?” Yet the PdM Technician can often point to a chart or spreadsheet logged days ago and say “I told you so”. Management’s perception is that the information was received too late. Yet, in reality, the data was there, but was not visible when it would be most valuable. Predictive maintenance activities generate massive amounts of data related to the health of the equipment. To be of real value to maintenance and operations, the data must be visible to maintenance, effectively analyzed while it’s still current, compared against defined “normal” states and the analysis communicated in a real-time manner. If you have time to “Predict Failure” you are very fortunately. Numerous studies over years shows 80% of a failures are random so when a PdM Tech identified a defect what step would you expect to be executed next?
We know from a reliability standpoint you cannot see or predict all equipment failures. However, most degradation in equipment performance can be observed well in advance with the integration of PdM technologies and techniques. Using handheld data collectors, operators and trades people can record real-time and time-stamped health indicators and feed that data into a computerized reliability system. The amount of data collected in any 8 hour shift is likely to be overwhelming if it was to be managed manually. And yet with appropriate computerization, the normal and non-normal state information creates the opportunity to selectively focus on only the handful of data points that are relevant each shift– where the asset health degradation is evident in the data. This form of data management can lead to the ultimate use of PdM capability, where management can easily make critical maintenance intervention decisions – driven by real-time data, before it is too late.
Reason 3: Many companies fail to take advantage of data from PLCs (Programmable Logic Controllers) and DCSs (Distributive Control Systems).
PLC’s and DCS’s can provide important production data such as pressure, flow and temperature that can also be useful for assessing asset health. Most of us think of PdM in the traditional sense; vibration analysis or oil analysis. Yet the production data available in most companies is quite extensive. We need to selectively tap into this valuable resource.
A cautionary word about production data; like other forms of PdM information, it’s only valuable if used in the context of a failure analysis. Most thorough failure analyses will point to production data as appropriate for understanding indicators of certain failure modes, while the majority of failure modes will rely on the collection of data through human senses. So hooking up a data-rich production database to a CMMS/EAM will only result in increasing the amount of useless data in making the right decision at the right time and help capture equipment historical data which is typically not accurate in most plants.
These more advanced PdM programs recognize where production data can add value, and they take advantage of the fact that it’s readily accessible electronically (for production use). Using this data, maintenance can better predict the degradation of equipment performance to determine the opportune time to intervene with proactive maintenance activities.
An example I was very familiar with as a maintenance supervisor was we had a DCS (Distributive Control System) which main function was to monitor the parameters of our production process and production equipment. We managed our production process using Statistical Process Control. Our DCS managed a lot of data and did a great job of it for production. What we missed was using specific data in this system to help maintenance make asset reliability decisions. I will use our rotary press as an example; the rotary press (calendar system) pressed two 300 CM rolls to form a matted product from woven fibers through this drum type press at speeds of over 500 meters per minute. The pressure of this rotary press had to stay constant in order to make the desired product. A complex hydraulic servo system was used to maintain the pressure required on this press in order to deliver the product required.
Our DCS monitored the hydraulic servo valve milliamp output as part of their process control measures. We checked (visual inspection by an electrician) daily the milliamp signals from all servos. We did not plot the data and relate the date to the PF Curve and thus the decisions we made on this system were either made too early or most the time too late. Reliability software now allow for continuous monitoring of the milliamp signals coming from these servos.
This data could have been collected real time, plotted and assisted in determining where on the PF Curve we needed to make a decision to change out a servo valve (based on the values from one servo valve controller) or the change out of the hydraulic pump (based on the values from numerous servo valves controllers) using reliability technology and methodology. With this new technology available a milliamp signal would be connected from the DCS to the Reliability Software where a decision can be made based on data with an alarm to the maintenance planner who plan and schedule a change out of a servo valve or pump far enough in advance that failures could have been kept at a minimum. This reliability software can be connected directly to the CMMS/EAM so that planning and scheduling of the work would be seamless and allow accurate history to be documented on the equipment.
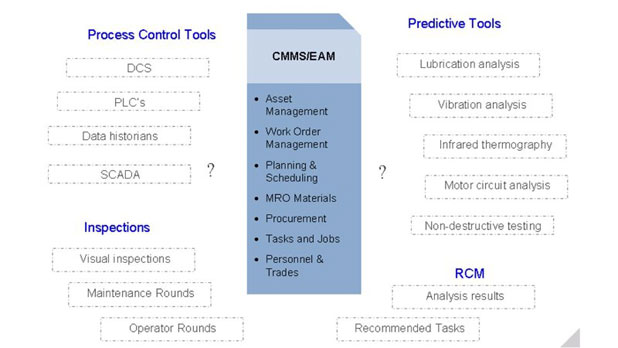
Reason 4: Most PdM data is dispersed in too many non–integrated databases.
Separate software systems are usually employed to manage the many specialized sources of PdM data: contractors have their data; the PdM team has several separate databases for each PdM technology, the production PLC’s and DCS’s also store required data. In addition, reliability engineers collect condition and state data from a variety of sources (typically as a result of a formal work identification process like RCM) and apply rules and calculations manually (day-after-day). Maintenance and operations personnel, themselves, are collecting and managing an increasing number of condition based proactive tasks in their own databases or often still on paper check-sheets. To act on this disjointed information from a variety of sources, it becomes impossible to realize significant value.
So what should you do about it?
With today’s technologies, all of these data sources can be integrated to enable timely maintenance decisions. Quite often, the best indicator of health is built using rules or calculations that combine data from multiple sources.
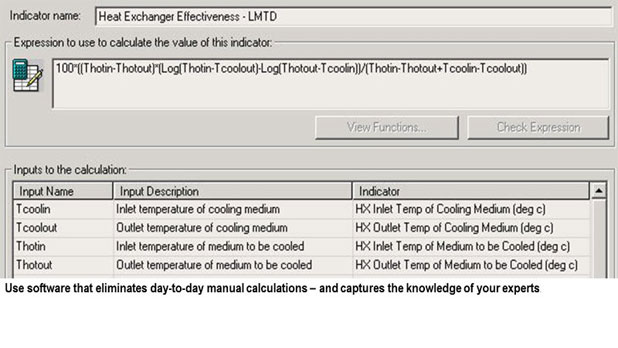
With a well integrated solution, maintenance can use real-time data to focus on defining the right proactive work to be performed at the right time.
Utilize systems that sort through normal and non-normal data, and display the results in ways that are easy to understand, and utilize.
Here is an example of a system that eliminates the sifting through piles of data. The plant, all of its assets and failure-mode-specific health indicators are displayed in a Health Indicator Panel, a two-panel screen showing the entire plant hierarchy and all assets on the left side, and relevant health indicators on the right side.
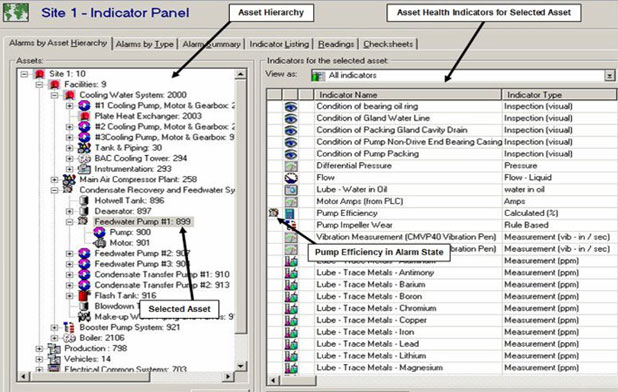
This panel allows you to monitor asset condition and, at a glance, see any indications of impending failures – before the failures occur. As non-normal values are recorded, alarms are triggered and displayed, drawing attention to only the few data points that currently signal the potential for equipment failure. These flashing alarms are displayed when assets are moving closer to functional failure and alarm severity are readily understood based on the type of icon displayed. Here corrective maintenance decisions can be made based on asset health and risk to the business.
Some simple guidelines will help to get you moving in the right direction:
- Do not stop what you currently are doing in Predictive Maintenance but evolve your PdM strategy into your maintenance program trading the adhoc wrong work at the wrong time to the “right work at the right time”. Do this by aligning your PdM work with the maintenance process required to keep your equipment reliable.
- Identify the most critical assets (those which are at highest risk to your plant) and focus on putting in place a PdM strategy within the context of a complete maintenance program for these assets. If you want make your PdM more effective, you need to know which assets are more important to monitor. Your PdM program will make an impact within the plant as quickly as possible and be a true contributor to asset reliability . When this new strategy is implemented you want “rapid results” which immediately gets people excited about what you are doing.
- Establish performance targets for these highest risk asset (focus on just one asset at a time) and measure the success of your new strategy. Performance targets must be in production terms: increased capacity, decreased downtime, etc. and in maintenance terms such as increased Mean Time Between Failure (MTBF).
- Work with operators, maintainers, and PdM technicians to assist in identifying known and likely failure modes on the highest priority assets. Develop a complete asset maintenance program of which PdM is an integral element.
- Implement this new PdM strategy within the context of a complete maintenance program on one asset at a time and monitor the results. If this process has been followed properly you should see results in a short period of time.
Summary
An effective PdM program must be integrated into a company’s asset reliability process so that the right decisions can be made at the right time utilizing accurate data which is fed into a reliability software which is in turn seamlessly linked to an effective CMMS/EAM. Being able to make reliability decisions far enough in advance to plan and schedule maintenance work will drive an organization from being reactive to proactive quickly thus allowing the company to meet it’s business goals 100% of the time.
The time has come for change. The best time to begin this new journey is “now”.
If you have questions or comments please send me an email to rsmith@peopleandprocesses.com.
Ricky Smith CMRP, CRL
Please comment and are appreciate even if you disagree. This is how we learn from each other, thanks: Ricky Smith
Tagged Predictive Maintenance, Ricky Smith

Pingback: pendaftaran cpns 2017